

Autoscale DuckDB fleets on demand.
DuckDB Quack is a fast, local-first SQL endpoint - but it ships without TLS, multi-tenancy, or external auth. Quack On Demand is the missing layer: an Arrow FlightSQL edge in front of pools of Quack nodes, with pluggable identity, table-level ACLs, role-aware routing, and a live admin console.
Spawn, place, and autoscale fleets of DuckDB Quack nodes on your own Kubernetes. Single tenant? Run it all as one Docker container on a single node.
A dedicated node per tenant with resource quotas and admission control. No noisy neighbors.
Table-level, column-level, and row-level security, plus dynamic data masking. Enforced on every statement.
What you get
Everything DuckDB Quack is missing in production.
DuckDB ships Quack as a minimal HTTP endpoint on localhost with a random token, and explicitly recommends a reverse proxy in front of it. Quack On Demand is that proxy - with the multi-tenancy, identity, and observability you need to actually expose it.
Arrow FlightSQL edge
Zero-copy result streaming over Apache Arrow Flight SQL - orders of magnitude faster than JDBC for analytical workloads. TLS is on by default and a self-signed cert is generated on first boot.
Multi-tenant pools
Spin up tenants and pools of DuckDB Quack nodes on demand. Each node is READONLY, WRITEONLY, or DUAL - the router classifies every statement and picks a compatible target.
Pluggable authentication
Database (bcrypt-hashed JDBC), external JWT (HS256/RS256/PEM), and OIDC providers - Keycloak (with ROPC), Google, Azure AD, AWS Cognito. Mix and match per deployment.
Postgres-relational ACL
Grants live in slkstate_acl_grant alongside DuckLake metadata. Principals expand to user / group / role at validation time so grants match whichever level of identity is stable.
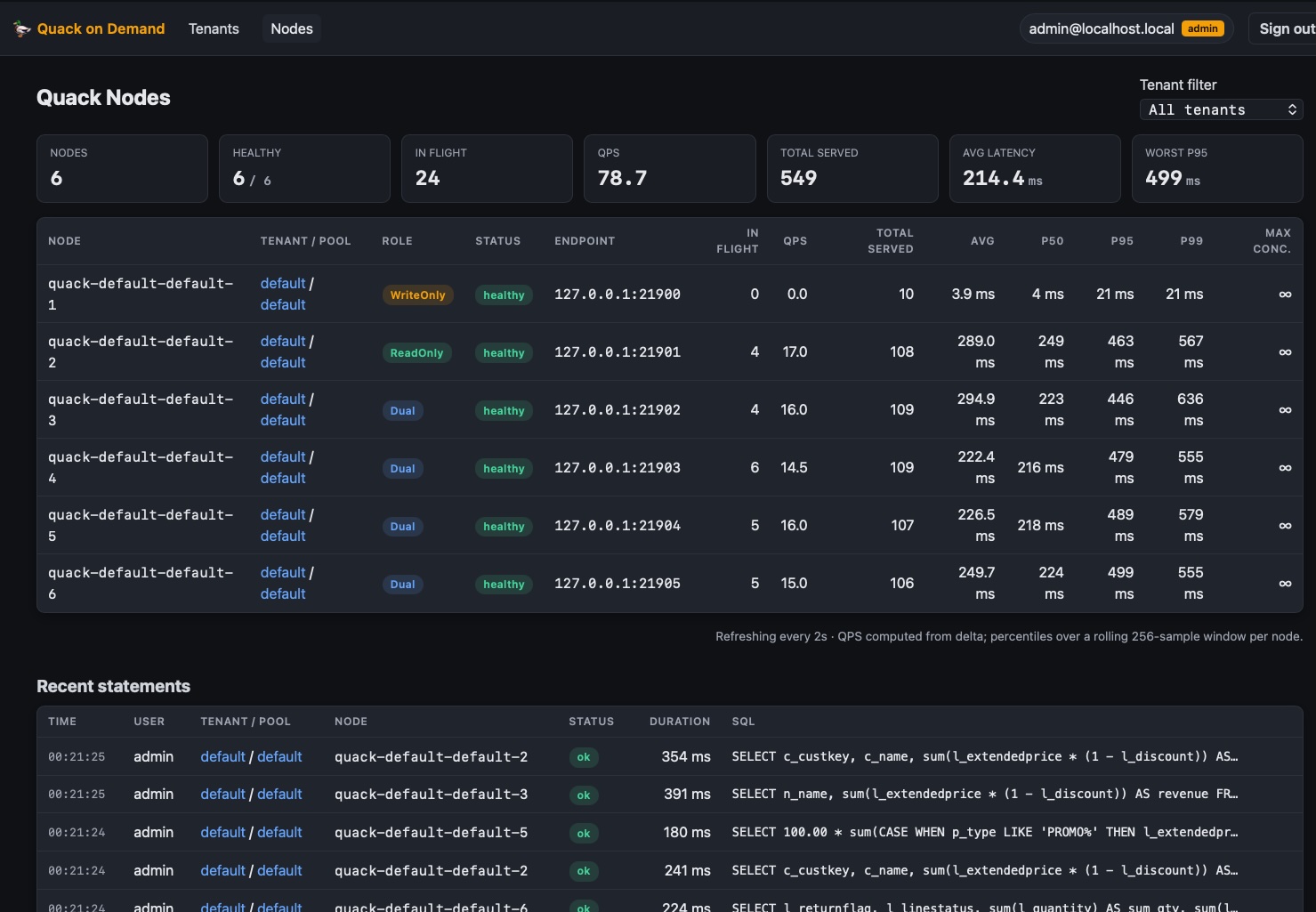
Live admin console
React dashboard at /ui/ - tenant + pool CRUD, per-tenant ACL editor, live node metrics (inFlight, totalServed, EWMA latency), admin-role gated.
Self-healing on restart
Dead Quack child processes are detected (PID + port probe) and respawned automatically before the edge accepts traffic. Manager restarts no longer strand the fleet.
Deployment
Single uber-jar
REST + React UI + FlightSQL edge in one process. State lives in Postgres next to DuckLake - no extra moving parts.
Configuration
Every key is overridable
Every scalar in application.conf accepts a matching SL_QUACK_* env-var. Build the image once, flip behavior per environment.
Runtime
Single container or Kubernetes
Single-node mode runs everything in one Docker container - ideal for single tenants, with Quack child processes on a port range. Kubernetes mode runs them as pods. Same control plane, same admin UI.
Query federation
One SQL surface over every source.
Quack On Demand turns DuckDB's federation into a governed, multi-tenant service. Point a query at your lake, your Iceberg warehouse, and your operational databases at once - and join them in place, without moving a byte.
Query data where it lives
Object storage, Iceberg tables, and operational databases are read in place. No copies, no nightly ETL, no second engine.
Join across sources in one statement
A single SQL query spans Parquet on S3, an Iceberg warehouse, and a Postgres table - DuckDB pushes down filters and streams results back over Arrow.
Governed like everything else
Every federated table reference passes the same per-statement RBAC and table-ref policy checks - federation never bypasses your ACLs.
-- One statement, three sources, zero copies
SELECT o.region,
c.segment,
SUM(o.amount) AS revenue
FROM read_parquet('s3://lake/orders/*.parquet') o
JOIN postgres_scan('crm','public','customers') c
ON c.id = o.customer_id
JOIN iceberg_scan('s3://warehouse/products') p
ON p.sku = o.sku
GROUP BY 1, 2;Bring your own pipeline
Works with any ETL, however you built your data.
QoD is a serving layer. It sits downstream of whatever produced your data. It does not care which tool wrote it, and it never routes your users anywhere.
Put DuckDB Quack in production without writing the auth, ACL, and routing layers yourself.
Boot the manager from a single uber-jar, point it at your Postgres metastore, and start serving FlightSQL queries to BI tools, ADBC clients, or Spark - with tenant isolation, table-level ACLs, and a live admin console out of the box.