Starlake OSS - Bringing Declarative Programming to Data Engineering and Analytics

Introduction
The advent of declarative programming through tools like Ansible and Terraform, has revolutionized infrastructure deployment by allowing developers to achieve intended goals without specifying the order of code execution.
This paradigm shift brings forth benefits such as reduced error rates, significantly shortened development cycles, enhanced code readability, and increased accessibility for developers of all levels.
This is the story of how a small team of developers crafted a platform that goes beyond the boundaries of conventional data engineering by applying a declarative approach to data extraction, loading, transformation and orchestration.
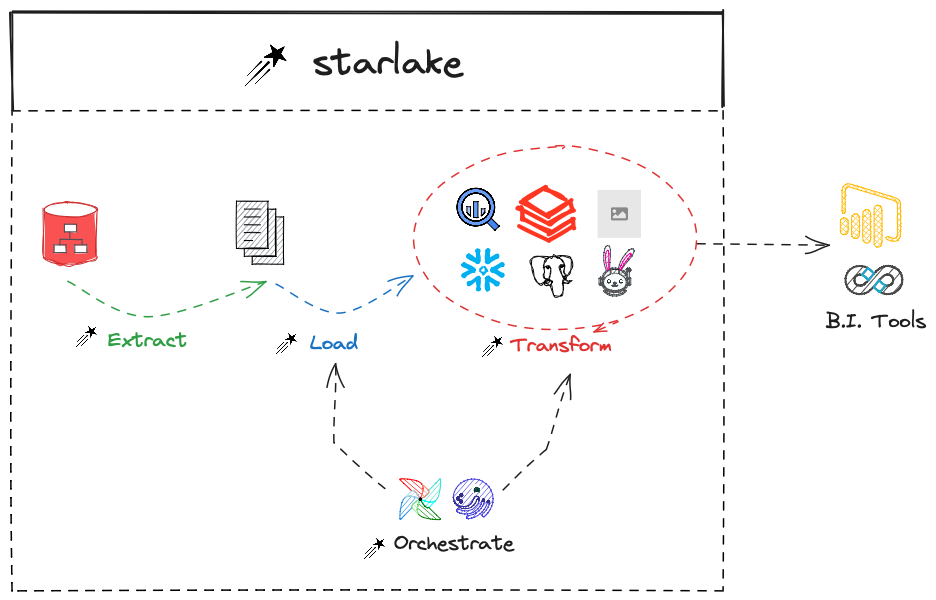
The Genesis
Back in 2015, at the helm of ebiznext, a boutique data engineering company, we faced a daunting challenge. Our client, a prominent entity in need of a robust big data solution, sought to harness the power of Hadoop and Spark. Despite our modest size (20 people), we dared to compete against industry giants with tenfold resources (100.000+ headcount).
Our only chance to succeed was to innovate: we needed a data platform that could exponentially outperform the traditional ETL solutions pushed by our competitors. To build data pipelines these GUI based ETLs require an effort that is proportional to the number and complexity of the sources.
Determined to disrupt this norm, we embarked on a quest to devise a DevOps friendly platform capable of lightning-fast data ingestion from any source, without the drawbacks of ETLs or specialized engineering skills.
The day of the tender, our ability to deliver a solution that could load data in a few weeks instead of many months allowed us to stand out from the competition and win the project.
Expisode 1: Smartlake Emerges
The basic idea behind Smartlake was that no datawarehouse would stay clean if data quality is checked after the data has been loaded and this pre-load quality checks needed to be handled by data owners.
This left us with little choice but to embrace the declarative approach. Empowering business users, we devised a system where data formats and transformations could be described in simple JSON files. Smartlake wasn’t merely a code generator; it was a versatile engine, seamlessly ingesting diverse data formats, executing transformations, and orchestrating operations with unparalleled efficiency.
To streamline user interaction, we devised an intuitive Excel-to-JSON converter, enabling effortless specification of input formats. Thanks to Smartlake and its declarative approach, the business users were able to define load and transformation operations in a matter of minutes.
Smartlake Standout features
-
Load almost any file format at Spark speed (CSV, JSON, XML, FIXED WITH, Multi-record types …) or Kafka topic
-
Validate fields using user-defined schemas with user defined semantic types
-
Apply transformations on the fly to data being loaded (GDPR, normalisation, computed fields ...) with and without schema evolution
-
Sink to almost any target including Spark, Kafka, Elasticsearch.
Episode 2: Evolution to Starlake
The basic idea behind Starlake was to bring in all Smartlake benefits to the cloud by leveraging serverless services and Cloud Datawarehouses capabilities while minimising development and execution costs.
As the data landscape evolved, so did our vision. Cloud data warehouses emerged as formidable competitors to Spark for query execution. Recognizing this shift, we evolved Smartlake into Starlake, preserving its declarative essence while embracing YAML for enhanced readability. We maintained Spark’s prowess to run inside single or multiple container(s) for data ingestion, leveraging cloud data warehouses for query execution.
This strategic blend allowed us to optimize performance and cost-effectiveness based on specific workload requirements. The result was a reimagined platform, tailored for the cloud era, yet grounded in the principles of efficiency and simplicity that defined its inception.
The result is the Starlake OSS project that you can find on Github.
The capabilities of Starlake are extensively described here.
The people behind Starlake
Smartlake, the precursor to Starlake, owes its existence to the collective efforts of numerous individuals, but a select few stand out for their exceptional contributions:
-
Sam Bessalah With Sam’s presence, rallying others became effortless. His visionary outlook and knack for simplifying complexities proved transformative, setting a new standard for implementation.
-
Olivier Girardot Every team has its coding wizard, and Olivier filled that role impeccably. From leveraging Spark codegen to exploring mathematical frameworks like matryoshka, he pushed the boundaries, mentoring the team with his expertise spanning Docker, Ansible, Python, Scala and Spark internals.
-
Valentin Kasas Valentin championed functional programming in Scala. Introducing concepts like recursion schemes, he empowered the team to craft code that was not just functional but also elegant and maintainable.
As the journey progressed towards the cloud, long time data experts joined and made Starlake what it is today:
-
Bounkong Khamphousone The speed and efficiency of Starlake’s extraction and load engines owe much to his contributions.
-
Mohamad Kassir His direct involvement with customer projects and his in-depth knowledge of cloud platforms and business needs have been major assets in the evolution of Starlake.
-
Abdelhamide EL ARIB An early contributor to the load engine, this foresight and execution prowess played a significant role in shaping the platform’s today capabilities.
-
Stephane Manciot The developer behind Starlake’s declarative workflows on top of Airflow and Dagster, was pivotal in shaping its operational backbone.
-
Cyrille Chépélov A master of codebase optimisation, Cyrille’s rewrite efforts were instrumental in ensuring the reentrant nature of Starlake’s API.
The next journey
Today with hundreds of gigabytes of data loaded and transformed daily into thousands of tables in various data warehouses, we can confidently say that Starlake is battle tested and ready for the most demanding data engineering & analytics challenges.
As Starlake is, and will always be open source, join us in building a supportive community. Your insights and feature requests aren’t just welcome, they guide our roadmap.
Get Started with Starlake:
-
Check-out the other features
-
Explore our documentation
Join our community on GitHub
P.S. Please star the repository: https://github.com/starlake-ai/starlake. Also, any issue or enhancement with Starlake, please just report it. It will fall under the scope of gracious care taking of course.