How to unit test your data pipelines

In today's data-driven landscape, ensuring the reliability and accuracy of your data warehouse is paramount. The cost of not testing your data can be astronomical, leading to critical business decisions based on faulty data and eroding trust.
The path to rigorous data testing comes with its own set of challenges. In this article, I will highlight how you can confidently deploy your data pipelines by leveraging Starlake JSQLTranspiler and DuckDB, while also reducing costs. we will go beyond testing your transform usually written in SQL and see how we can also test our Ingestion jobs.
The art of mastering data pipelines
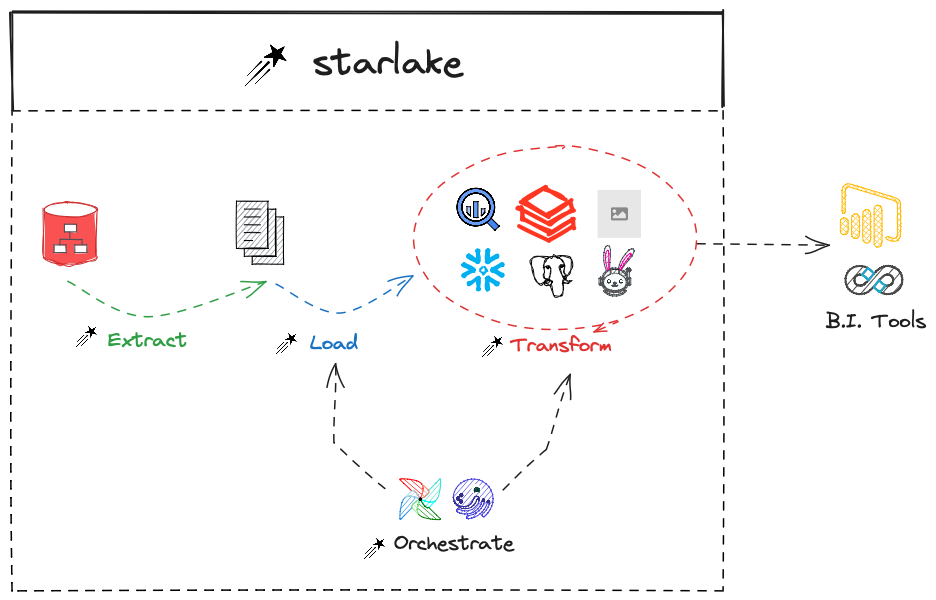
Mastering your data pipeline is a challenging art. A data pipeline generally contains the following phases:
- Collection: Extracting data from sources
- Ingestion: Loading the extracted data into the data warehouse
- Transformation: A phase that ultimately adds value to the collected data
The table below summarizes the tests run by Starlake on Load & Transform jobs:
| Check to run on | Ingestion Test | Transform Test |
|---|---|---|
| Validate the filename pattern | ✓ | |
| Validate the file structure (number and types of attributes, input file format - CSV / JSON / XML / FIXED-WIDTH) | ✓ | |
| Check if loaded files or transform SQL SELECT statements are materialized according to the defined strategy (APPEND / OVERWRITE / UPSERT_BY_KEY, SCD2 …) | ✓ | ✓ |
| Check for missing or unexpected records in the resulting table | ✓ | ✓ |
| Check if the resulting table has a correct schema | ✓ | ✓ |
| Check all expectations | ✓ | ✓ |
| Check time based query output with time freeze | ✓ | ✓ |
| The results of these automated tests are designed for both human review and CI/CD integration. For human review, a website is generated to help users easily identify failures and their causes. For CI/CD integration, a JUnit report is generated, and there is an option to specify a minimum coverage threshold. If the evaluated coverage falls below this threshold, the command will result in an error, and any failing tests will also trigger errors. |
Untested SQL costs
Thanks to data pipelines unit testing, we drastically reduce the development cost. Not running tests seems to allow high project's velocity, thereby delivering value quickly. However, the cost of a feature does not stop at its simple development but encompasses all the efforts put in until the feature's completion. Below are some hidden costs.
- Identifying bugs
- Without unit tests, verifying development requires deploying the project. This deployment raises challenging questions about the deployment strategy and its rollback or correction procedures.
- Verification might be carried out by a separate QA team, sometimes even outside the project team. This can lead to the use of feature flags to avoid deploying to production, complicating the implementation. Additionally, waiting for feedback from the QA team introduces delays, increasing the cost of fixing any bugs that arise.
- Depending on the deployment strategy, verification may also be incomplete due to a lack of control over the test data used.
- Maintenance and Evolution Complexity
- Many of us have faced a massive query and struggled to make modifications without disrupting existing functionality, all while aiming for improvements like optimizing processing time. Rigorous unit tests can help with this. They allow us to enhance the expected outcomes in current datasets, create new ones, and compare the modified query results with these expectations. This significantly reduces the risk of regression.
- Decreased productivity
- The absence of automated tests often means manually re-running parts or all of the system to ensure correct integration, which can lead to spending time fixing collateral bugs and thus reducing overall productivity. As the project advances, more components need verification, making the process even more time-consuming. This significantly diminishes the willingness to refactor or revise code.
- Promoting expertise
- Without unit tests, teams often assign the same tasks to the same people, which hinders skill development and increases the risk of knowledge loss due to turnover.
- Customer dissatisfaction
- A project with uncertain product output quality often leads to dissatisfaction, frustration, and a loss of trust in the individual, the team, or the product.
We are all aware of the hidden costs associated with the absence of tests; in my opinion, these are the most significant. Therefore, we will explore how to manage a data pipeline.
Writing unit test in Starlake
Suppose we have the following transform.

We test it by creating the following hierarchy:

This is then how it is executed

Starlake unit tests benefits
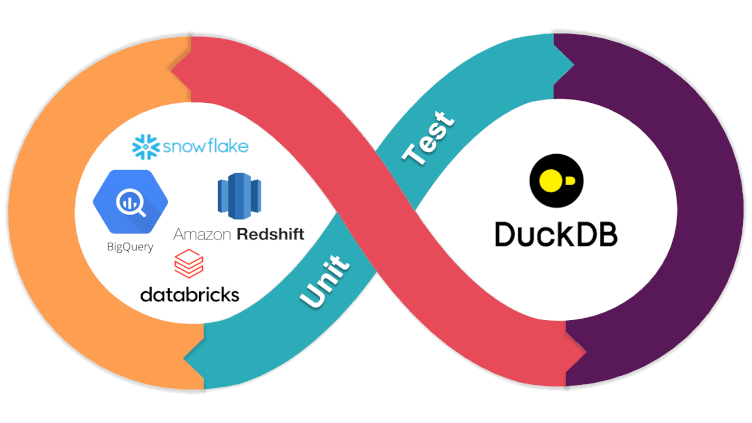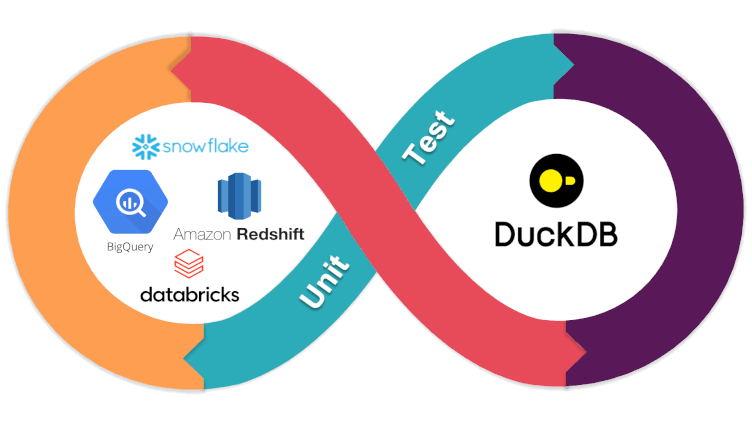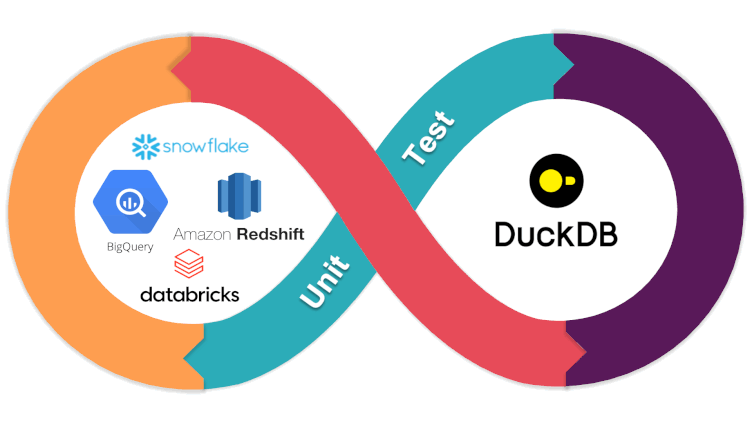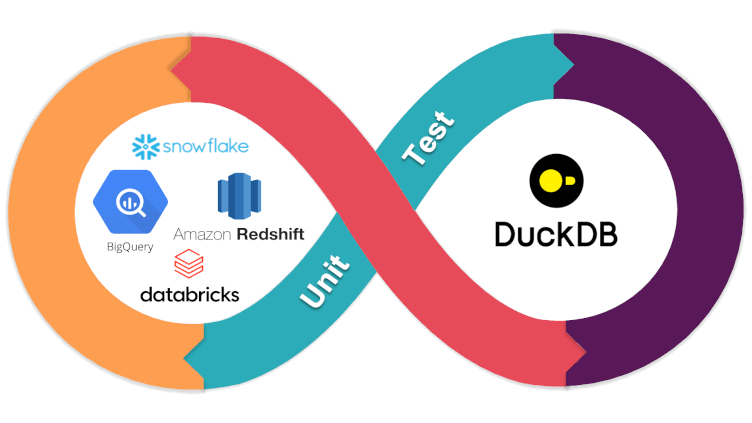
Running tests on a local DuckDB database instead of the target Data Warehouse has the following advantages:
- Fast Feedback: Local execution is significantly faster than using a remote database due to network latency. Additionally, the local environment might be better suited for handling small volumes of test data.
- No Execution Cost: Depending on the pricing model of the target database, creating temporary resources and executing queries can incur both execution and storage costs.
- Setup and Cleanup of Automated Tests: Guarantee of resource isolation.
- Credential Issues: Running tests against a target database requires credentials, which may pose security risks.
Conclusion
In this article, we have demonstrated how adopting unit testing, a crucial practice for software engineers, can significantly enhance the quality of our data pipelines. This approach not only reduces overall costs in the medium to long term but also ensures the maintenance of dynamic and enduring documentation. Additionally, implementing unit tests is essential for rigorous CI/CD processes, enabling seamless continuous data pipeline deployment.
If you encounter any issues while performing your tests locally, please report them on the Starlake GitHub repository. Your feedback is invaluable in improving local test coverage, empowering more data engineers to deploy their work confidently and smoothly. For further discussions and support, join our team on Slack.
We greatly appreciate your contributions. If you found this article helpful, please star the project on GitHub and share it on your social networks to help us reach a broader audience.